
Paper Summary
Abstract and contribution
Recent advances in vision-language models have enabled mobile GUI agents to perceive visual interfaces and execute user instructions, but reliable prediction of action consequences remains critical for long-horizon and high-risk interactions. Existing mobile world models provide either text-based or image-based future states, yet it remains unclear which representation is useful, whether generated rollouts can replace real environments, and how test-time guidance helps agents of different strengths.
We filter and annotate mobile world-model data, then train world models across four modalities: delta text, full text, diffusion-based images, and renderable code. We evaluate their downstream utility on AITZ, AndroidControl, and AndroidWorld.
Finding 1Renderable code is strong in-distribution; text feedback is more robust for online OOD execution.
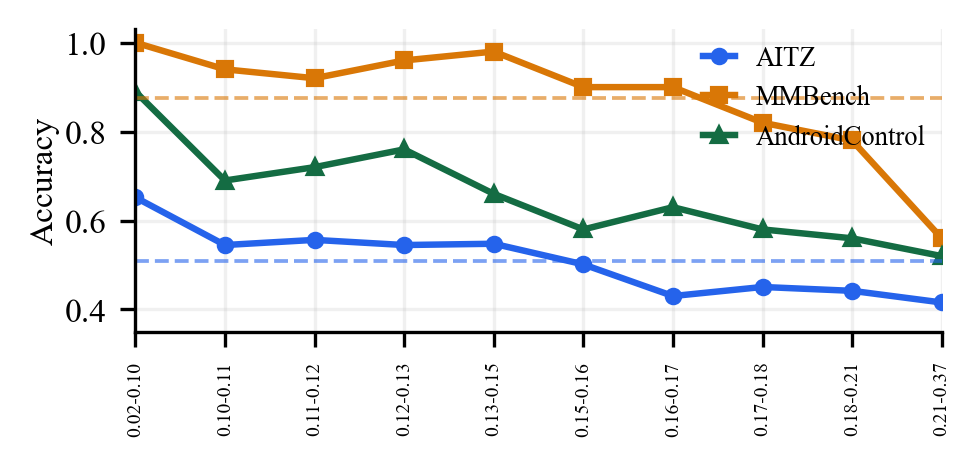
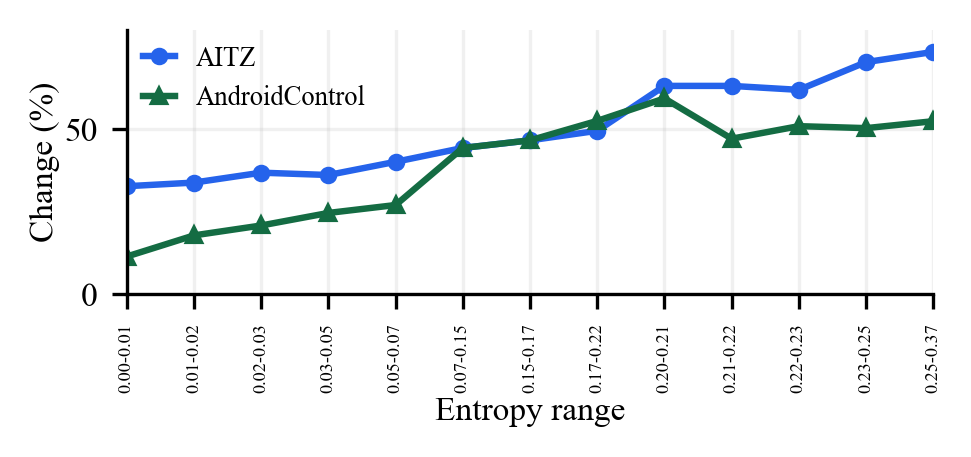
Finding 2Posterior self-reflection is limited by overconfident, low-entropy action policies.
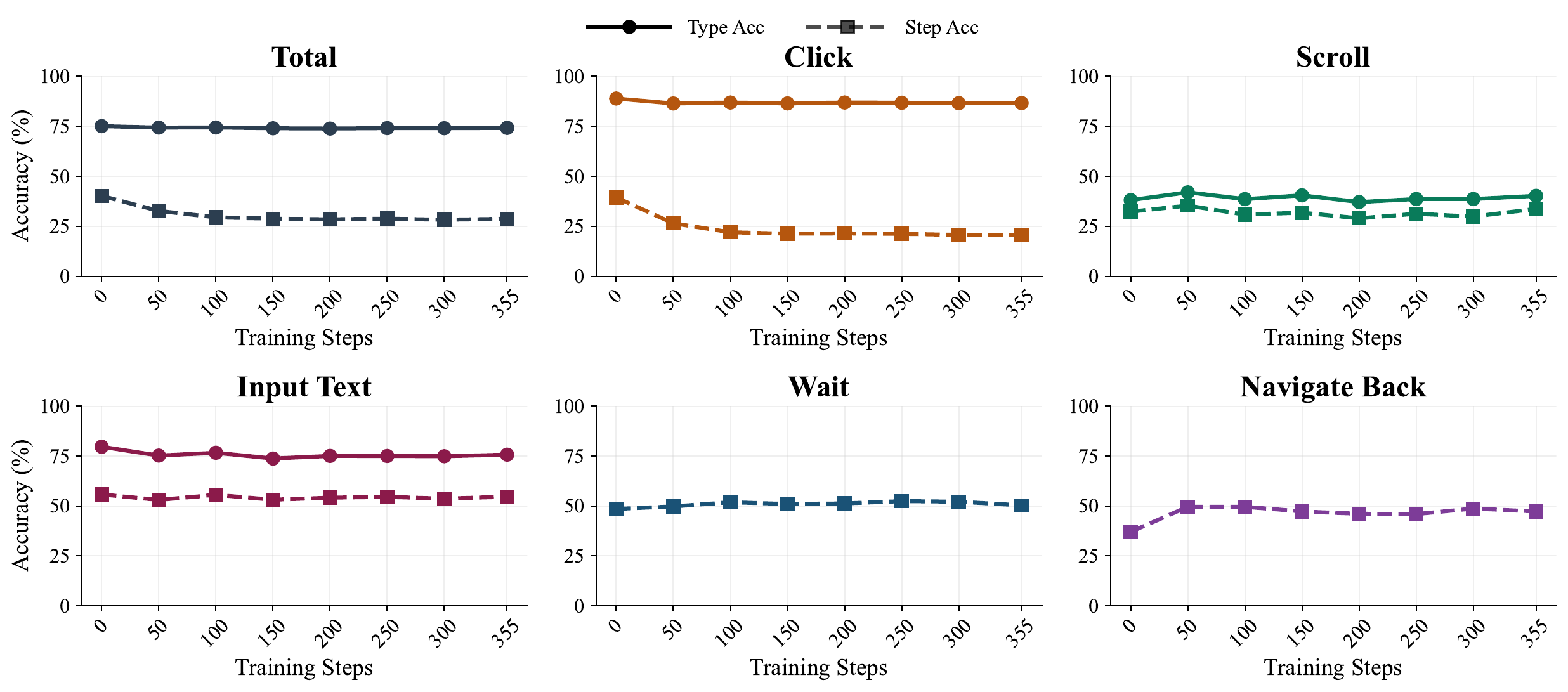
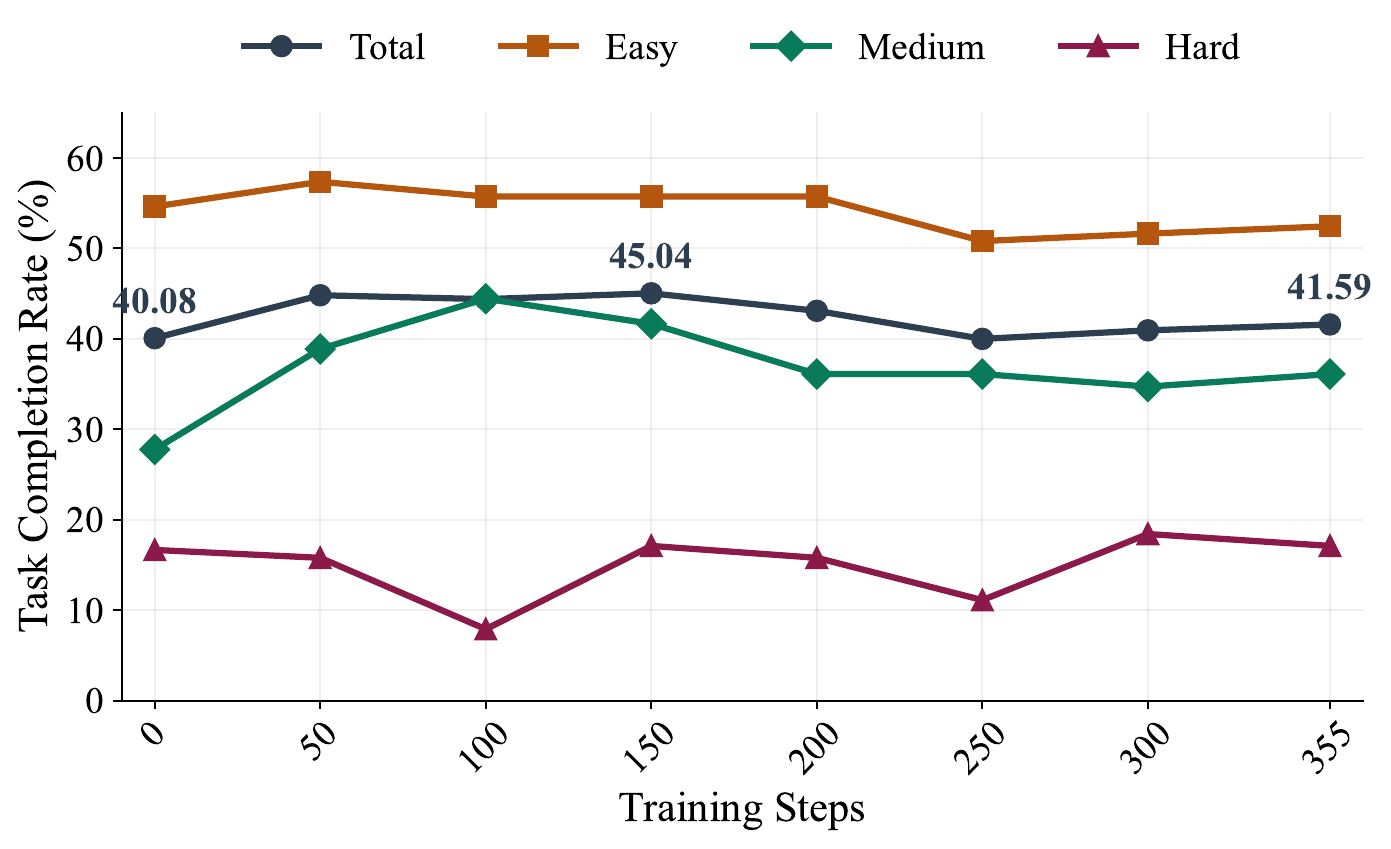
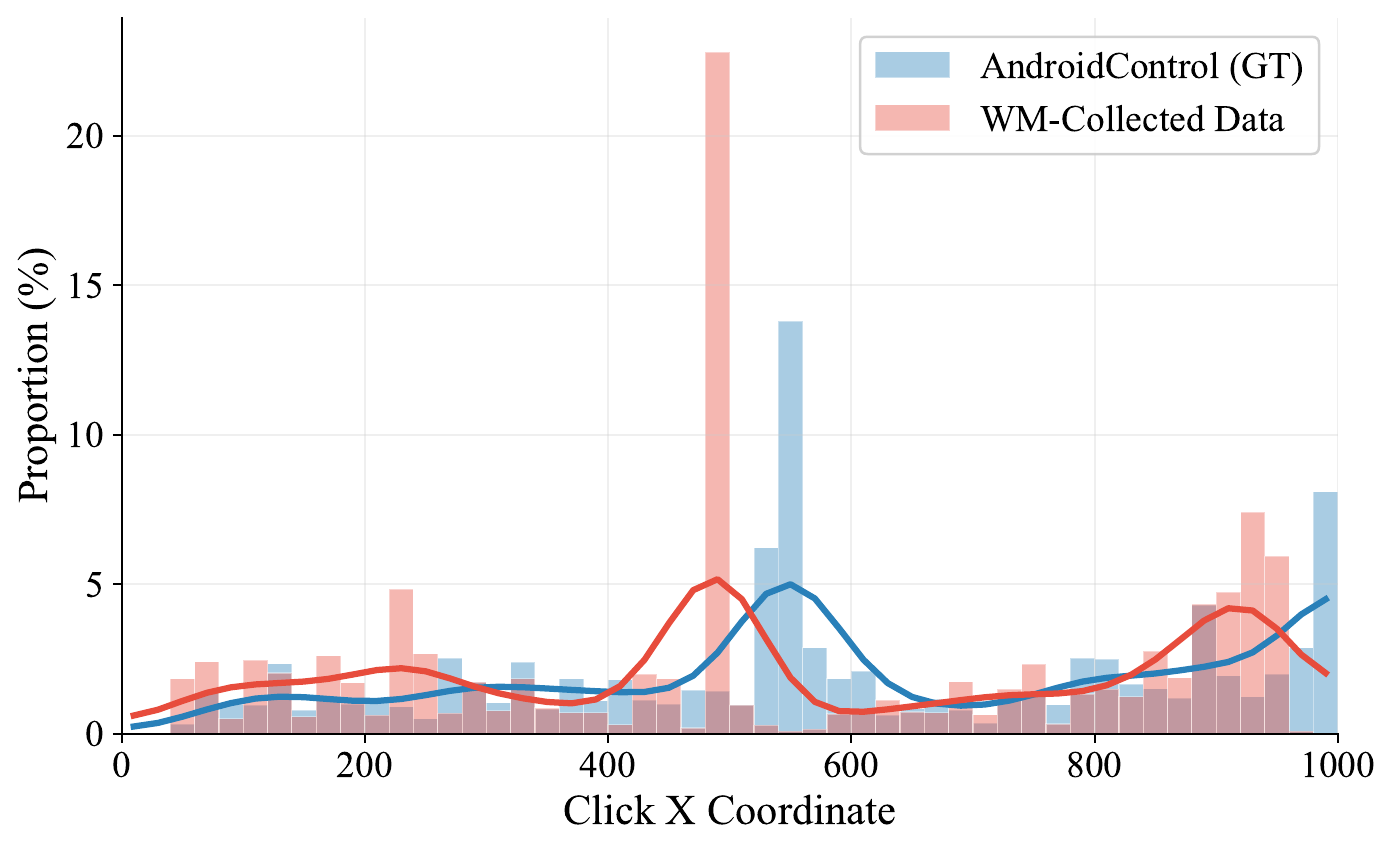
Finding 3World-model imagination can transfer interaction experience, but does not preserve the source distribution.
Intro Figures
World-model formats and headline results


Three Experimental Conclusions
What the experiments show



Qualitative Cases
Where the world model helps and fails





Stopwatch · real UI

Stopwatch · imagined render

Account · real UI

Account · imagined render